고정 헤더 영역
상세 컨텐츠
본문
728x90
SVM
*Characteristic
◼ SVM은 이진 분류기이다.
◼ SVM은 많은 실생활에서 성공적으로 사용되고 있다.
텍스트(및 하이퍼텍스트) 분류
이미지 분류
생물정보학(유전자 분류, 암)
손으로 쓴 문자 인식
◼ SVM은 회귀 분석, 특이치 분석, 순위 등에 적용되었다.
*Scatter Plot of Training Dataset
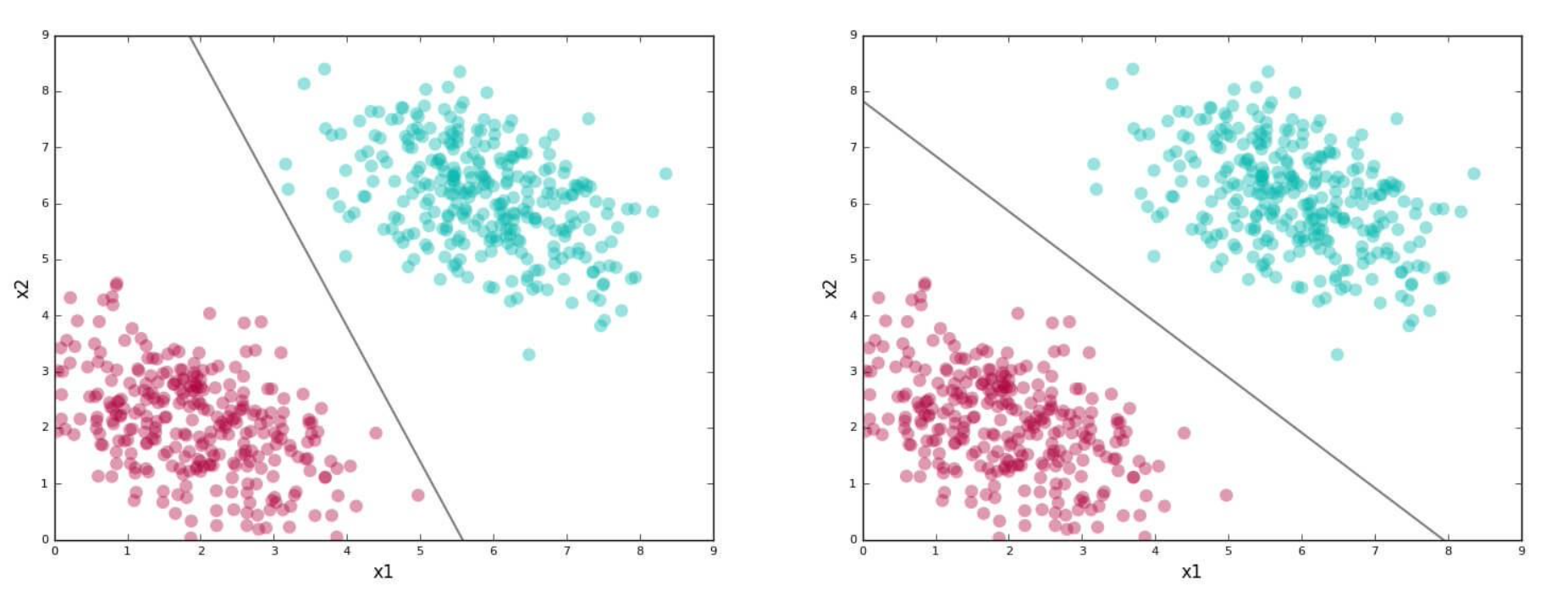
아래의 선형적으로 분리 가능한 2차원 dataset을 이용해 SVM을 적용해볼 것이다. 빨간색과 초록색을 분리하는 선은 무수히 많지만 그 중 두개를 보여주자면 다음과 같다.

빨간색과 초록색을 분리하는 선은 무수히 많지만 그 중 두개를 보여주자면 다음과 같다. 그리고 각 선은 classifier 또는 separating boundary 라고 한다. 아래 첫 번째 그림의 classifier은 "skewed"되어있다. 두 번째 그림의 classifier가 테스트 데이터 세트에 대해 정확하게 예측할 가능성이 더 높다.
*Computational Objectives of SVM
◼ training dataset을 올바르게 분류하는 선(또는 평면)을 찾는다.
◼ 이러한 모든 분리 선(또는 평면) 중에서 여백이 가장 넓은 선을 선택한다.
◼ 이러한 선은 두 군집을 가장 명확하게 구분한다.
*Key Definition
- separating line (= plane = decision boundary = classifier): training data의 두 군집을 구분하는 선 (아래 그림에서 검은색 선)
-support vector: 분리선을 식별하는 가장 가까운 데이터 점 (아래 그림에서 가장자리가 검은색인 데이터 점 두 개)
-margin: 선을 중심으로 정의되는 영역 (아래 그림에서 음영 처리된 영역)

*Problems & Solutions
아래 그림처럼 빨간색과 파란색 데이터 지점이 중앙 영역에 혼합되어 있는 경우 구분선을 찾을 수 없다.

1. Soft Margin
◼ margin을 좁히거나 일부 분류 오류(즉, margin 내의 일부 데이터 포인트 허용)를 허용하는 것이다.
◼ soft margin을 활용하기 위해 사용자는 "C"라는 패널티 파라미터를 제공할 수 있다.
◼ "C"는 SVM의 하이퍼 파라미터 중 하나이다.
◼ C의 높은 값은 분류 오류에 대한 높은 패널티를 의미한다.
◼ 이는 좁은 margin training dataset의 낮은 분류 오류를 의미한다.
◼ C 값이 낮으면 margin이 크고 분류 오류가 높다는 것을 의미한다.
◼ 최상의 "C" 값을 cross validation을 이용해 찾는다.
아래 그림에서 C 값이 증가함에 따라 마진 폭과 방향이 변화하는 것을 볼 수 있다.

-Scikit-Learn Code Using "C"
# default penalty
clf = svm.SVC(kernel='linear', C=1)
# less penalty
clf2 = svm.SVC(kernel='linear', C=0.01)
2. Kernel Trick
◼ 커널 함수를 사용하여 데이터 집합을 선형적으로 분리할 수 있는 고차원 공간에 "투영"한다.
◼ 그 공간에서 hyperplane을 찾는다.
◼ 커널은 SVM의 하이퍼 파라미터 중 하나이다.
-Kernel Functions
◼ Linear kernel (default)
◼ Polynomial kernel with degree d

◼ Gaussian kernel (also called radial basis function (RBF) kernel (with width s)

◼ Sigmoid kernel (with parameters k and q)

아래 그림은 kernel function이 decision boundary에 미치는 영향을 보여준다.

*Advantages
◼ 분리 범위가 명확할 때 정말 잘 작동한다.
◼ 고차원 공간에 효과적이다.
◼ 경계 결정 계산에서 지원 벡터만 사용하기 때문에 메모리 효율적이다.
*Disadvantages
◼ 필요한 training 시간이 더 길기 때문에 대규모 데이터 세트의 경우 성능이 좋지 않다.
◼ dataset에 노이즈가 많을 때, 즉 target class가 겹칠 때 잘 수행되지 않는다.
◼ 확률 추정치를 직접 제공하지는 않으며, k-fold cross validation을 사용하여 계산된다.
*Choices for SVM
◼ 커널 선택 (Gaussian or polynomial kernel is default)
◼ 커널 매개 변수 선택 (e.g. gamma, σ in Gaussian kernel)
◼ 최적화 기준(hard vs soft margin, C parameter)
◼ 다양한 매개 변수가 테스트되는 긴 일련의 실험
*Scikit Learn Code for SVM
# import libraries
from sklearn.svm import SVC
from sklearn.metrics import classification_report, confusion_matrix
from sklearn.model_selection import train_test_split
# (omitted) import dataset
# split the dataset into train set and test set
X_train, X_test, y_train, y_test = train_test_split(X, y,test_size = 0.20)
# create an SVC classifier model
svclassifier = SVC(kernel='linear')
# fit the model to train dataset
svclassifier.fit(X_train, y_train)
# make predictions using the trained model
y_pred = svclassifier.predict(X_test)
# evaluate the model
print(confusion_matrix(y_test,y_pred))
print(classification_report(y_test,y_pred))*Multi Class Classification Using Binary Class Classification
Logistic Regression과 SVM은 이항(2-class) classifier이다. multi-class classification은 모든 binary classification의 출력을 결합하여 수행됩니다.
◼ 일반적으로 One vs All 방법이 사용된다.
◼ 그러나 데이터가 매우 클 경우 One vs One이 사용된다.
◼ One vs One에는 더 많은 이진 분류기가 필요하지만 데이터 세트는 더 작은 하위 집합으로 분할되며 모든 이진 분류기를 만드는 것이 더 빠르다.
◼ Skikit-learn은 SVM이 다중 클래스 분류에 사용될 것을 감지할 때 One vs One 방법을 사용한다.
1. one vs all
N-class classification을 위해 N binary classifiers 가 필요하다.

2. one vs one
N-class classification을 위해 N*(N-1)/2 binary classifiers가 필요하다.

* Using Scikit-Learn for logistic regression-based multiclass classification
# uses built-in one vs all
from sklearn.datasets import make_classification
from sklearn.linear_model import LogisticRegression
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, n_classes=3, random_state=1)
# define model
model = LogisticRegression(multi_class='ovr') # fit model
model.fit(X, y)
# make predictions
yhat = model.predict(X)
* Using Scikit-Learn for SVM-based multiclass classification
from sklearn.datasets import make_classification
from sklearn.svm import SVC
# define dataset
X, y = make_classification(n_samples=1000, n_features=10, n_informative=5, n_redundant=5, n_classes=3, random_state=1)
# define model
model = SVC(decision_function_shape='ovo') # fit model
model.fit(X, y)
# make predictions
yhat = model.predict(X)728x90
'machine learning' 카테고리의 다른 글
| [ML] Clustering Algorithms –Expectation-Maximization (Gaussian Mixture Model) (0) | 2022.12.15 |
|---|---|
| [ML] Clustering Algorithms – Partitioning (0) | 2022.12.15 |
| [ML] Clustering Algorithms – Clustering Quality Measure (2) | 2022.12.14 |
| [ML] Classification Algorithms – Logistic Regression (0) | 2022.12.13 |
| [ML] Classification Algorithms –Decision Trees (2) | 2022.12.12 |





댓글 영역